Foreign Accent Conversion by Synthesizing Speech from Phonetic Posteriorgrams 2019.7
[译]从PPGs合成语音进行外国口音转换
https://www.semanticscholar.org/paper/Foreign-Accent-Conversion-by-Synthesizing-Speech-Zhao-Ding/8386d03827eabc8446883cd16e46ef10d3d318d4
0. 摘要
外国人口音转换(FAC)目标是生成一个语音听起来与被给的非母语者相似,但是拥有母语者的口音。过去的FAC方法在合成时借用了来自参考语句(母语)的激励信息(F0 and aperiodicity; pro-duced by a conventional vocoder)。使用这样的方法,合成的声音保留了母语者声音质量的一些方面。我们展示了一种方法,摒弃了过去使用的Vocoder与母语者的激励(excitation)。我们的方法使用一个在母语者语料上训练的声学模型用于抽取独立于说话者(Speaker-independent)的PPGs,而后训练一个语音合成器将来自非母语者的PPGs映射到对应的谱特征上,该谱特征可以通过一个高质量的神经Vocoder依次转换为声音波形。运行时,我们使用从母语者语句中抽取的PPGs作为参照驱动合成器{1}。听力测试表明,与基线系统相比,该系统产生的语音更清晰、更自然、更接近非母语者,同时显著降低了非母语者的感知外国口音。
{1} 用native的PPGs训练合成器
{注1}模型组成:1. 语音识别模型用于抽取非母语者的PPGs | 2. 语音合成器用于将抽取出的非母语者PPGs合成为与母语者更相似口音的谱 | 3. Vocoder
{注2}训练部分:SR模型与合成器都使用native数据训练
{注3}转换部分:输入non-native语音片段,得到与母语口音更相似的新片段。
关键字:phonetic posteriorgram, acoustic modeling, speech synthesis, accent conversion
00. 图片
1. 概述
FAC的目标是创造一个新的声音用于被给的非母语者的音质{1}及母语者的发音模式(如,韵律和停顿)。它可以通过结合来自母语语音片段的口音相关特征(accent-related cues, arc)和非母语者的音质来实现。FAC可以应用于电脑辅助的发音训练,在其中充当模型声音用于模仿。
FAC的主要挑战是如何从语音信号中分离arc与音质。已有多种解决方案被提出,包括语音变形[3,6-8]、帧配对[1,9]和发音合成[2,10-12]。这些方法可以减少非母语者的口音,但都有许多局限。语音变形合成的语音常常听起来像是不同于任何说话者的第三者说的。帧配对方法可以合成类似于非母语者语音的语音,但合成保留了母语者音质的某些方面;这是因为母语者的激励信息(excitation information)被用在了语音合成中。最后,发音合成需要专门的设备来收集发音数据,因此在实际应用中并不实用。
{1} In the context of FAC, we use voice quality to refer solely the organic aspects of a speaker’s voice, e.g., pitch range, vo-cal tract dimensions.
{注} FAC的三种传统方法:语音变形[3,6-8]、帧配对[1,9]和发音合成[2,10-12]
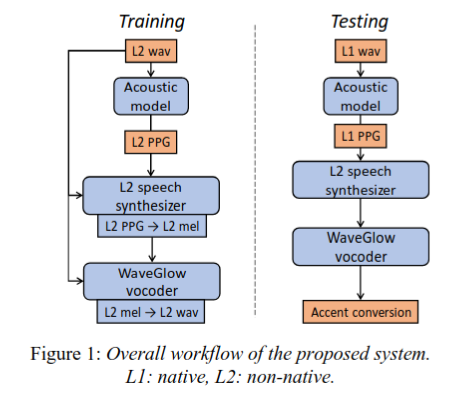
在这项工作中,我们建议在不依赖说话者的语音丰富语音嵌入--语音后验图(PPGs)中执行FAC[13]。PPG被定义为每一个语音帧属于一组预先定义好的音素单元 (phonemes or triphones/senones)的后验概率,其包含了语句的语言信息和语音信息。 我们的方法具体工作如下。第一步,我们使用独立于说话者的在大型母语语音基础上训练的声学模型为非母语者生成一个PPGs。随后,我们构建一个Seq2Seq的语音合成器用于抓取非母语者的音质。这个合成器使用来自非母语者的PPGs序列作为输入,处理得到对应的梅尔谱图(Mel-spectrogram)作为输出。最后,我们训练一个神经语音编码器(Vocoder),WaveGlow,用于将梅尔谱图转化为原始的声学信号。{!!}在测试中,我们向合成器中输入一个来自母语者的PPG序列。输出结果包含母语者的发音模式以及非母语者的音质。提出系统的工作流程总览见Figure 1。
{!!}如果是这样的系统根本没法做到直接去使用
{注} 也就是说整个训练过程都是一个对说话者音质的建模
{思考}那如何对单一母语者的重音特点/发音模式建模呢?
该提出的系统有三个优点。首先,它消除了从母语参考语音中借用激励信息(excitation information)的需要,从而防止了母语者语音质量的某些方面渗入到合成语音中。第二,我们的系统不需要任何训练数据来自母语的参考说话者。因此,我们可以在测试中灵活的使用任何参考语音。第三,我们的系统通过一个顺序到顺序的模型捕获上下文信息,该模型在多个任务上显示了最先进的性能,在次帮助下获得了更好的音质。
2. 相关工作
{机翻}
口音转换的早期尝试使用语音变形[3,6-8]通过混合来自母语和非母语说话者的频谱成分来控制口音的程度。 在[18,19]中,作者使用PSOLA修改了口音语音的持续时间和音高模式。 Aryal和Gutierrez-Osuna [1]修改了语音转换(VC)技术,将动态时间规整(DTW)替换为根据声道长度归一化后基于源和目标帧的MFCC相似度来匹配源和目标帧的技术。 后来, Zhao et al. [9]使用PPG相似度代替MFCC相似度用于配对声帧。
PPG已应用于许多任务,例如,基于神经网络的语音识别[20,21],语音检测[13],发音错误[22]和个性化TTS [23]。 PPG在VC中也引起了很多关注。 Xie et al. [24]将来自目标说话者的PPG划分为群集,然后将来自源说话者的PPG映射到目标说话者的最近群集。 Sun et al. [25]使用PPG进行多对一语音转换。 Miyoshi et al. [26]扩展了基于PPG的VC框架,以包括使用LSTM在源PPG和目标PPG之间的映射。 与不包含PPG映射过程的基准相比,他们获得了更好的语音个性评级,但音频质量较差。Zhang et al. [15]将源说话者的瓶颈特征和梅尔谱图串联起来,然后使用序列到序列模型将源梅尔谱图转换为目标说话者的谱图,最后使用WaveNet [27]恢复语音波形。 声码器。 他们的模型需要并行录音,并且需要为每个扬声器对训练一个新模型。 然后,他们应用文本监督[28]解决了转换后语音中的一些错误发音和伪影。 最近,Zhou et al. [29]采用双语PPG进行跨语言语音转换。
3. 方法
我们的系统由三个主要构建组成;一个独立于说话者的声学模型(acoustic model, AM)用于抽取PPGs,一个非母语说话者的语音合成器用于将PPGs转换为梅尔谱图,和一个WaveGlow声码器用于实施地从梅尔谱生成语音波形。
3.1. AM与PPG抽取
我们使用具有多个隐藏层和p范数非线性的DNN作为AM。我们在一个母语语音语料库上,通过最小化output与由一个预训练的GMM-HMM强制对准器获得的{!}senone label的交叉熵,来训练AM。在母语语音上训练对我们的任务来说是至关重要,因为母语和非母语的帧必须在母语语音空间中匹配。
{!}用的是senone,(phonemes or triphones/senones)
3.2. PPG2Mel
我们使用改良的Tacotron 2 [32]将来自非母语者的PPG转换为它们相应的梅尔频谱图。
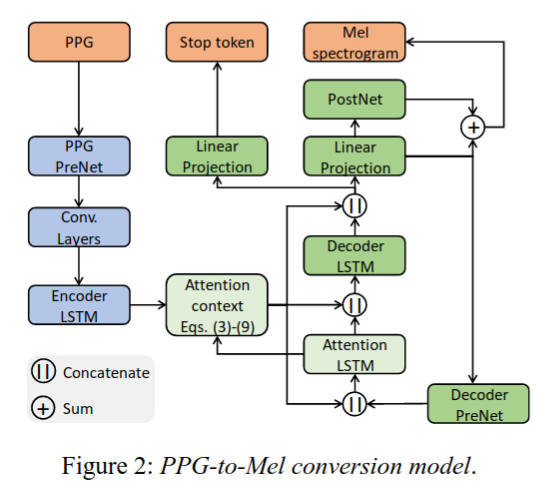
{1-1}原始的Tacotron 2模型采用字符(characters)的one-hot矢量表示(vector representation),并将其传递到encoder LSTM,后者将其转换为隐藏的表示(hidden representation),然后将其传递到具有位置敏感注意机制的decoder LSTM [33],来预测字符的梅尔谱图。{左蓝↑4->右橙↑2,3}
{1-2}为了提高模型性能,将character embedding经过多个卷积层后,再输入到enconder LSTM中。{左蓝↑1,2,3layers}
{1-3}Decoder在将预测的mel谱图传递给attention之前附加一个PreNet(two fully connected layers),而后decoder LSTM提取结构信息。{右橙↑1,2}
{1-4}它还在解码器之后应用了PostNet(multiple 1-D convolutional layers)用于预测频谱细节并将其添加到原始预测中。{右橙↑4}
{1} Tacotron 2理论
{2}在这里的工作中,我们使用(包含two fully connected hidden layers with the ReLU nonlinearity)PPG-embedding network (PPG PreNet)替代character-embedding layer。这个PPG-embedding network 与Tacotron 2中的PreNet相似,将原始输入的高维度的PPGs变换为低维度的bottleneck features。这一步对模型的收敛至关重要。PPG2Mel 转换模型详见Figure 2。
{2}使用PPGs作为输入代替字符
{3}原始的Tacotron 2 接收一个字符序列作为输入,显然这要比我们的PPG序列短。例如每一个我们语料库的句子平均包含41个字符,然而PPG序列却有几百帧。因此,原始的Tacotron 2注意机制会被如此长的输入序列所混淆,并导致PPG和声音序列之间的不一致,例如 [15]。结果,推论将是病态的,并且将产生不可理解的语音。{3-1}一种解决该问题的方法是使用更短的PPG序列训练PPG2Mel模型。例如,一种是可以用词组代替句子。然而,这种解决方法有一些问题。首先,为了获得正确的词语边界,我们需要强制对其训练的句子,这需要获取转码。第二,更重要的是,使用短片段训练进行长输入序列的预测会导致模型失败,例如[33]。
{3-2}我们通过在注意机制中添加一个局部约束来解决这个问题。语音信号具有很强的时间连续性和渐进性。为来抓取语音上下文,我们只需要在局部的小窗口中观察PPGs。受此启发,在训练过程中的每一个解码步骤中,我们都将注意力机制限制为查看隐藏状态序列中的窗口,而不是查看完整序列。我们正式定义这个约束如下。定义\(d_i\)为decoder LSTM的第\(i\)步输出,\(y_i\)为预测出的声学特征(是对\(d_i\)应用线性投影后的output),\(h = [h_1,...,h_T]\)是来自encoder的hidden states的整个序列。应用局部敏感的注意机制,我们得到, 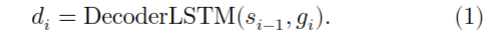
这里的\(s_{i-1}\)是attention LSTM第(i-1)步的hidden state,\(g_i\)是attention context,
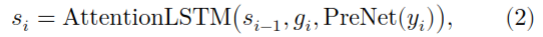
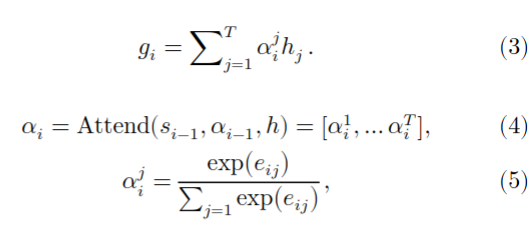
都是attention weights。attention scores \(e_{ij}\)计算方法如下
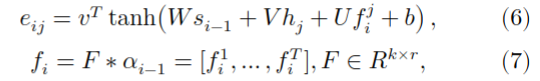
这里 \(v, W, V, U, b\) 都是attention module的可学习参数(learnable parameters)。\(F\) 包含\(k\)个一维(1-D)可学习的带有\(r\)-dims的内核,\(f_i^j ∈ R^k\) 是在\(j\) 位置上将 \(F\) 与 \(a_{i-1}\) 卷积的结果。
现在,为了实施局部性约束,我们只考虑以当前帧为中心的固定窗口中的隐藏表示,例如:
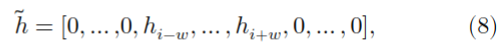
这里的\(w\) 是窗口大小,接着
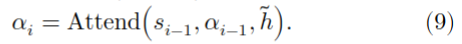
PPG2Mel模型的损失函数如下:
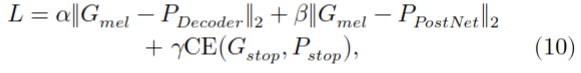
这里\(G_{mel}\) 是真实值的mel-spectrogram;\(P_{Decoder}\) 和\(P_{PostNet}\) 是分别来自decoder(after linear projection) 和PostNet。\(G_{stop}\) 是真实的stop token,\(P_{stop}\) 是预测的stop token;\(CE(∙)\) 是交叉熵损失;\(\alpha, \beta, \gamma\) 控制每个损失项的相对重要性。
{3}由于序列过长导致注意力机制出错
{3-2}解决方法:将注意力机制限制为查看隐藏状态序列中的窗口,而不是查看完整序列
{3-2}详述了attention方法的基本原理!!!
3.3 Mel2speech
我们使用WaveGlow声码器将语音合成器的输出转换回语音波形。WaveGlow是一个flow-based的[35]网络,能够从mel频谱图生成高质量的语音(与Wave Net相当)。它从零均值球面高斯(方差\(\sigma\))中抽取与期望输出具有相同维数的样本,并将这些样本通过一系列层,这些层将简单分布转换为具有期望分布的分布。训练一个声码器的情况下,我们使用WaveGlow对mel谱图上的音频样本分布进行建模。WaveGlow只需一个神经网络就可以实现实时的推理,而WaveNet由于其自回归特性,需要很长的时间来合成一个话语。有关WaveGlow声码器的更多详细信息,请参阅[14]。
4. 实验和结果
4.1 实验步骤
我们使用Librispeech corpus[30]来训练AM。该语料库包含960hrs的英文母语语音, 大多数是来自北美的。AM有五个隐藏层和一个有5816个senones的输出层。我们在两个来自L2-ARCTIC的非母语者语料上{1}训练PPG2Mel和WaveGlow模型。我们使用Audacity[36]对原始的L2-ARCTIC记录进行降噪处理,目的是去除环境背景的噪声。对于母语参考语音,我们使用了来自ARCTIC语料库[37]的两名北美说话者BDL(M)和CLB(F)[37]。 L2-ARCTIC和ARCTIC的每个发言者都收录了相同的一组1132个句子,或大约一个小时的演讲时间。对于每一个L2-ARCTIC的说话人,我们使用前1032个句子进行模型训练,接下来的50个句子用于验证,剩下的50个句子用于测试。所有音频信号均在16 KHz下采样。我们使用了80个滤波器组,以10ms的位移和64ms的窗口来提取mel谱图。也以10ms的位移提取PPG。
{注-1} 本段说明了语料信息,和样本处理方法
{1}关于非母语者语料的描述:YKWK (na-tive male Korean speaker) and ZHAA (native female Arabic speaker) from the publicly-available L2-ARCTIC corpus [34].
在Table 1.中总结了PPG2Mel模型的参数。我们使用6的批量大小(batch size)和1×10 -4的学习率(learning rate)。 \(\alpha,\beta,\gamma\) 分别根据经验设置为1.0、1.0和0.005。 注意机制的局部性约束的窗口大小 \(\omega\) 设置为20。我们训练模型,直到验证损失达到平稳(〜8h)。
对于WaveGlow模型,我们根据[14]的建议在训练过程中将 \(\sigma\) 设置为0.701,在测试过程中将 \(\sigma\) 设置为0.6。 批次大小为3,学习率为1×10 -4。 训练模型直到收敛(约一天)。 所有模型都在单个Nvidia GTX 1070 GPU上进行了训练。

使用Kaldi训练AM,及其他模型用PyTorch上实现,使用Adam optimizer训练。更多细节和音频样本,请参考https://github.com/guanlongzhao/fac-via-ppg。
{注-2}本段说明了部分模型参数
我们将提出的系统与如下构建的baseline[9]进行比较。首先,我们计算每个native和non-native frames 的PPG。然后,我们在PPG空间中只用symmetric KL divergence对最接近的native帧和non-native帧进行配对。在最后一步中,我们从帧对中提取Mel倒谱系数(MCEPs)来训练joint-density GMM(JD-GMM)spectral conversion ,如[39]所述。然后,我们使用JD-GMM转换了native MCEPs,以匹配非母语者的voice quality。最后,我们使用STRAIGHT Vocoder[40]从转换后的MCEPs结合母语者的非周期性(aperiodicity,AP)和F0(归一化为非母语者的音调范围(pitch range)来合成语音。我们在基线系统中使用了同样的1032个发音训练集。GMM包含128个混合矩阵和全协方差矩阵。我们使用24维MCEPs(不包括MCEP0)和Δ特征。所有特征均以10ms位移和25ms窗口直线提取。对于每个系统都使用说话者BDL-YKWK和CLB-ZHAA语料做重音转换。
{注-3}baseline system的构建方法。
4.2 结果
[半机翻]
我们进行三种听力测试来比较系统的表现: 音频质量和自然度的Mean Opinion Score (MOS) 测试,声音相似度测试,口音测试。所有测试都在Amazon Mechanical Turk上进行,所有的参与者都是美国居民。每一个测试,来自不同系统的每个说话者的25个语句对(总共50个)被随机选择。样本的出现顺序在所有实验中都是随机的。
音频质量和自然度的MOS测试的分数是五分制的(1-bad, 2-poor, 3-fair, 4-good, 5-excellent)。音频质量和自然度的MOS分别描述了语音的清晰度和与人类的相似度。这两个测量是从不重叠的听众群体中获得的,以避免偏见。每个音频样本至少收到17个分数。听众还将对同一组北极和L2北极原始录音进行评分以作为参考。结果汇总在Table 2.和Table 3.中。值得注意的是,在[9]中,我们确定了基线系统的音频质量MOS比使用DTW进行帧配对的传统JD-GMM系统大约高0.4。因此,我们的基线比传统的JD-GMM更强。
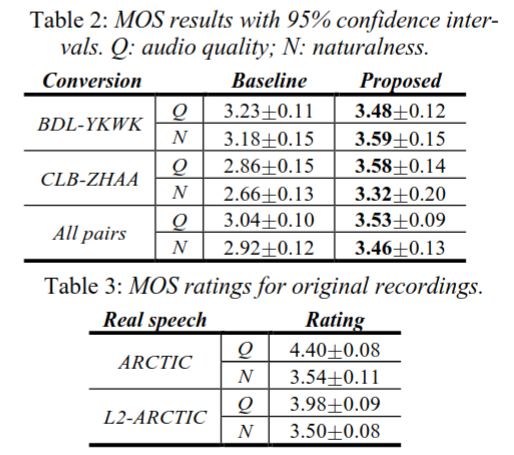
在所有情况下,我们的系统在音质和自然度方面都明显优于基线。尽管这两个系统的音频质量MOS都要低于原始记录(语料库的原始音频),但在自然度MOS上,无论是ARCTIC(\(p\)=0.35)还是L2-ARCTIC(\(p\)=0.54),使用双尾双样本t检验,提出的系统都没有显著差异。
在语音相似性测试中,给听者提供了三个话语,即原始的非母语话语和来自两个系统的合成语,并要求他们选择哪一个合成语听起来更像非母语者。参与者还被要求在做出选择时,用7分制(1分表示完全不自信,7分表示极度自信)来评定他们的置信水平。参与者被要求在执行任务时忽略口音。在每次试验中,来自两个系统的样本的呈现顺序是平衡的,17名参与者对音频样本进行评级。结果见Table 4.。在72.47%的案例中,听者以3.4的置信水平(高于“somewhat confident”)选择提议的系统,而在其余27.53%的案例中,听者以低很多的置信评分(1.05,或“完全不置信”)选择基线系统。

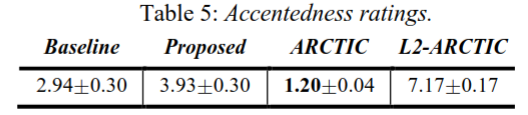
在口音测试中,参与者被要求用九分制(1分为非外国口音,9分为非常强的外国口音)对外国口音的程度进行评分,这是发音文献中常用的方法[43]。每个音频样本由18个人评分。结果汇总在表5中。ARCTIC 说话者的原始话语被评为“没有外国口音”(1.20),而L2-ARCTIC 说话者的原始话语被评为重口音(7.17)。基线系统(2.94)和提议的系统(3.93)与第二语言北极语相比显著降低了外国口音,但被评为比本国口音更重。令人惊讶的是,我们的系统生成的语音被评为比基线系统更重的口音;有关此结果的潜在解释,请参见讨论部分。
5. 讨论与结论
提出的AC系统处理的语音要好于基线系统,这得益于它使用了最先进的Seq2Seq模型(a modified Tacotron2)将PPGs转换为Mel-spectrograms,同时使用了一个神经声码器(neural vocoder)直接从mel谱图生成音频信号。该方法利用了语音信号的时变特性,避免了传统的基于信号处理的会降低了合成质量的声码器的使用。我们还提出了一种易于实现的注意机制的局部约束,使PPG-to-Mel模型在话语层面(utterance-level)样本上可训练。请注意,我们的MOS数值低于原始Tacotron 2和WaveGlow纸张中的MOS数值,这主要是因为它们的系统接受了24倍以上的数据训练。提高系统MOS数值的一个未来方向是联合训练PPG-to-Mel和WaveGlow模型。{1}
{1}如何提高MOS值
与从母语者那里借用激励信息(F0,AP)的基线形成对比,我们的系统直接从合成后的mel谱图中生成了非原生说话者的激励。 这样可以防止母语使用者的语音质量渗入到合成中,使合成语音与非母语使用者的音质更加相似。
我们的系统从本地PPG序列中提取母语的发音模式,因此使合成语音的口音明显低于非母语的语音。与基线系统相比,口音(accentedness)评分的轻微增加可能是两个因素的结果。{2}首先,AM(acoustic model)在提取PPG时不可避免地会产生识别错误,这些错误将在合成中反映为发音错误。其次,该模型没有明确地模拟重音和语调模式,因此,我们发现一些合成结果有意想不到的语调。因此,在未来的工作中,我们计划将信息整合到建模过程中;{2-1}一种可能的解决方法是在训练和测试PPG-to-Mel模型时,将PPG序列置于一个标准化的F0循环(contour)中。
{2}为什么出现口音评分反而轻微增加的情况
{2}原因:模型存在AM系统识别不稳定,及没有明确对母语发音建模的问题
{2-1}上述问题可能的解决方法
目前,{3}PPG-to-Mel和WaveGlow模型需要非母语者至少一小时的语音。可以使用多说话人TTS的迁移学习范式来减轻这一需求。{4}AC的最终目标是在合成时消除对参考音的需要,即获取非母语者的语音并自动减少其口音。这可以通过学习一个从非母语者的PPG序列到母语者的PPG序列的Seq2Seq的映射来实现,然后使用这个口音减少的PPG序列驱动PPG2Mel合成器。
{3}如何简单训练数据负担 {3-1}通过一些迁移学习范式
{4}如何在合成时消除对参考音的需要 {4-1}直接学习一种Seq2Seq的映射